Een spraak-Brain-Computer Interface
Het doel van mijn onderzoek is het bouwen van de ultieme interface tussen computers en mensen door neurale signalen direct te interpreteren om computers te besturen of met behulp van computers te kunnen communiceren. In het bijzonder wil ik een spraak-BCI, (een spraak-Brain-Computer Interface) bouwen die hersenactiviteit meet en deze direct vertaalt in spraak. Zo’n spraak-BCI zou patiënten die door een beroerte of motorneuronziekte hun spraakvermogen hebben verloren, weer kunnen communiceren met vrienden en familie.
Meestal trainen we zo’n BCI door trainingsgegevens te verzamelen van de beoogde gebruiker, die eenzelfde gedrag keer op keer uitvoert. In het geval van spraak-BCI’s willen we graag parallelle opnames van hersenactiviteit en spraak hebben om machine learning algoritmes te trainen die de hersenactiviteit bij spraak in kaart brengen. Idealiter zouden op deze manier vele uren training verzameld worden om sterke en betrouwbare decoders van hersenactiviteit te bouwen. Helaas is dit proces vaak niet mogelijk omdat patiënten die zo’n spraak-BCI nodig hebben, niet meer kunnen spreken en dus geen spraak kunnen leveren.
Idealiter zouden we de kracht van moderne diepe neurale netwerken gebruiken voor de decoderingstaak van hersenactiviteit naar spraak door duizenden uren aan trainingsgegevens te gebruiken. Om dit mogelijk te maken, moeten we twee problemen aanpakken:
(1) Verzamel grote hoeveelheden hersentrainingsgegevens van zoveel mogelijk deelnemers. Als referentie worden automatische spraakherkenningssystemen routinematig getraind op honderdduizenden uren aan gegevens.
(2) De neurale gegevens, opgenomen in zeer heterogene hersenen, op één lijn brengen met een gemeenschappelijke structuur. Toegang krijgen tot natuurgetrouwe neurale opnames is niet eenvoudig. De beste resultaten worden behaald wanneer de elektroden zo dicht mogelijk bij de interessante hersengebieden zijn geplaatst. Echter, het implanteren van elektroden alleen om gegevens te verzamelen is niet ethisch. Mijn groep lift daarom mee op klinische procedures waarbij elektroden worden geïmplanteerd voor de monitoring van een behandeling, bijvoorbeeld bij epilepsie, de ziekte van Parkinson of tumoren. Door met deze patiëntgroepen te werken, kunnen we misschien een gegevensverzameling opzetten die groot genoeg is om de kracht van Deep Learning in te zetten voor BCI’s. Gedurende meerdere jaren kunnen we honderden uren aan gegevens verzamelen. Door samen te werken met andere centra kan dit worden uitgebreid tot de duizenden uren die nodig zijn voor Deep Learning.
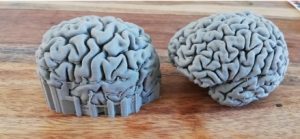
Figuur 1: Twee 3D-prints van hersenen. Let op de sterk verschillende corticale anatomie.
Als de vereiste hoeveelheid gegevens eenmaal is vastgelegd, moeten we nog steeds algoritmen ontwikkelen die de onderliggende processen kunnen generaliseren uit al die volledig verschillende individuele corticale architecturen. Bekijk als voorbeeld de 3D-modellen van mijn hersenen en de hersenen van een van mijn collega’s in afbeelding 1. Het is duidelijk te zien dat het ene brein er anders uitziet dan het andere. Door de onderliggende representatie van hersenprocessen te identificeren die consistent is voor alle patiënten, zouden we spraak-BCI’s kunnen bouwen die werken voor alle patiënten die dat nodig hebben.