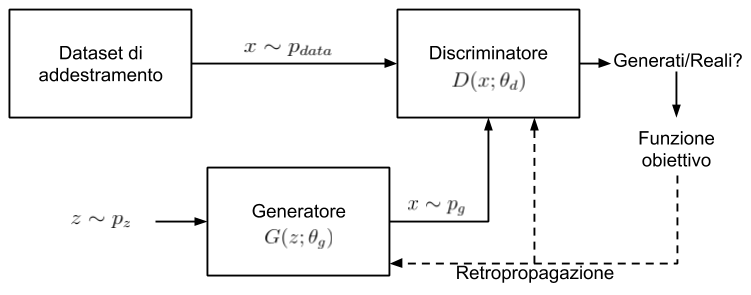
‘Data is het nieuwe olie’: de digitale wereld drijft op data. Alle algoritmes die een ervaring op het internet verbeteren, of überhaupt mogelijk maken, hebben data nodig – net zoals onze fysieke wereld vaak brandstof verbruikt. Die digitale data komt in verschillende vormen, maar de meest voorkomende én meest waardevolle vorm is tabular data. Dat is data die je in een tabel kan plaatsen, zoals bijvoorbeeld de likes die je uitdeelt op een sociaal medium, je koopgedrag met je credit card of nog persoonlijker: je gehele medische geschiedenis. Omdat tabular data heel gedetailleerd kan zijn is het ontzettend waardevol. En dat is dan ook gelijk het nadeel: hoe gedetailleerder tabular data wordt, hoe meer de privacy van gebruikers in het geding komt. Samen met co-founders Iman Alipour en Edwin Kooistra en ondersteund door Delft Enterprise is Lydia Chen BlueGen.ai gestart om daar wat aan te doen, door te werken aan synthetische data. En net als synthetische olie moet synthetische data de wereld een stuk schoner maken.
“Onze nieuwe algoritmes kunnen op een betrouwbare manier ‘nepdata’ maken die statistisch identiek zijn aan originele datasets. Zulke ‘nepdata’ kun je zorgeloos delen, je deelt immers geen privégegevens. (…) We beseften allemaal dat we met synthetische data in één keer drie grote problemen kunnen oplossen: je kunt datasets zonder moeite vergroten, waardoor je snel inzicht krijgt in patronen waardoor je de juiste vragen kunt stellen – maar misschien wel het belangrijkste: datahonger hoeft niet meer ten koste te gaan van privacy!”
“Ik ben er van overtuigd dat al in de vrij nabije toekomst 20 tot 30% van de data synthetisch is.”
Lees het hele stuk op de site van de TU Delft.